MacKenzie Scott's giving, in QALYs
An interactive cost-effectiveness model for MacKenzie Scott's $26B in philanthropy — and the AI prompts that built it.
Visit project →
MacKenzie Scott gave away $7 billion in 2025 — about a third of every megagift in America that year, by the Indiana University Lilly Family School of Philanthropy’s count. Almost none of it is denominated in health. I built an interactive tool that asks what her $26 billion in lifetime giving buys in the unit health economists use to compare lives — quality-adjusted life-years: maxghenis.com/mackenzie-scott-qaly. Drag the assumptions and a Monte Carlo cost-effectiveness model reruns in your browser; on the skeptical default it lands around 205,000 QALYs — a model output, not a measured fact, which is why the tool exists: move the assumptions yourself.
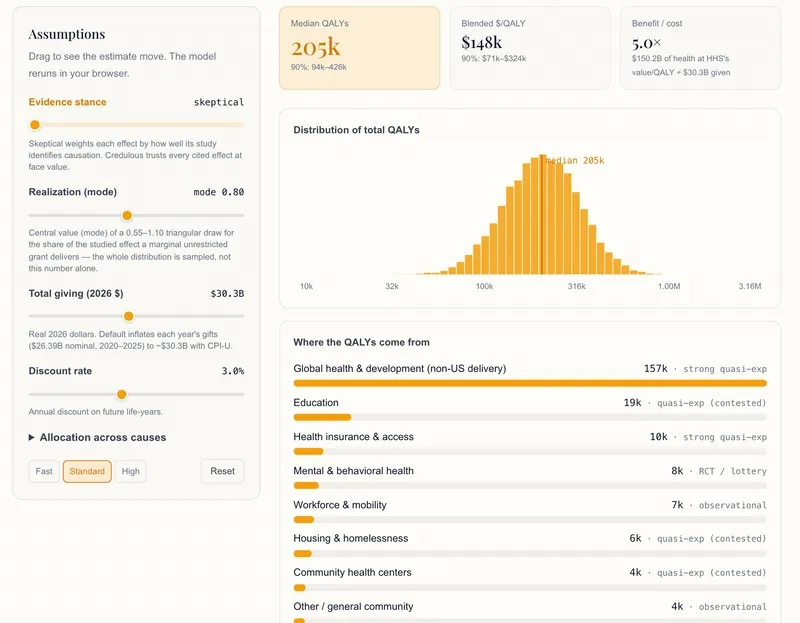
It runs the same machinery as the GiveWell cost-effectiveness replication I built in February — editable parameters, Monte Carlo, sensitivity analysis — pointed at a different question. GiveWell scores the most cost-effective charities in the world. This points the same lens at one donor’s actual $26B portfolio, most of it unrestricted gifts to US organizations, where almost none of the spending is denominated in health to begin with.
Why I care about the gap
I took the Giving What We Can pledge in 2019 for one reason: the global poor benefit far more from a dollar than I do. This tool puts a number on that for Scott’s giving. Measured purely in health, a dollar at the global-health frontier — bed nets averting child deaths — buys roughly 500 times the QALYs of her blended portfolio. That’s a marginal comparison; redeploying the full $26 billion would compress it toward the floor — around 20–40× even if every dollar became direct cash — the tool page works through the arithmetic.
How much that gap should bother you is the open question, and the QALY count doesn’t settle it. Part of the gap is outside her control: preventing a death costs far more in a rich country than a poor one, and a QALY ignores the income, opportunity, and rights her giving targets. Part of it is a choice: $26 billion is enough that where it goes carries real opportunity cost, measured in lives. The tool hands you the number, not the verdict. It’s the same arithmetic that sends my own giving abroad.
Two models, arguing
I built this with two coding agents, and the more useful part was letting them check each other. Claude Code wrote the model and the tool. Then I had Codex review the assumptions cold: it caught a real error — a cost-per-life figure I’d left in old dollars without inflating it — and disagreed with Claude on whether the global benchmark belongs in QALYs or DALYs. I’m centralizing on QALYs. Two models disagreeing about a modeling choice is a sharper adversarial review than either alone.
Two further full review rounds (both models, against everything) caught more, and the fixes moved the headline from ~98,000 to ~87,000: gifts are now recorded as the exact disclosed tranches and inflated to 2026 dollars year by year instead of divided nominal-vs-current; the community-health-center figure now uses the paper’s own ~$54k per life-year with an explicit life-year→QALY conversion (the old version skipped it); several 2000s-era cost-effectiveness anchors got inflated to current dollars; the frontier benchmark was re-derived twice — first for discounting consistency, then onto GiveWell’s current program averages — cutting the headline multiple by about 40%; the benefit/cost ratio now uses HHS’s published value per QALY instead of a per-life-year value applied to QALYs; and one citation was re-attributed to the paper the numbers actually come from — Sommers (2017), verified against the PDF, after I’d confidently planted the wrong one. Every correction made the model more skeptical or more honest, none was caught by a human, and the errors had survived earlier review passes.
The allocation across causes was still my prior, though — I’d accepted “Scott doesn’t publish dollars-by-cause” without checking hard enough. She publishes better: Yield Giving’s gift database itemizes dollar amounts for about two-thirds of the money, with focus areas on every disclosed dollar. Deriving the split from her own data — 53 org-reported areas mapped onto the model’s 13 archetypes, every rule documented — cut the skeptical median from ~87,000 to ~70,000. Her real portfolio holds less food, housing, and cash assistance than I’d assumed (the buckets with the strongest health evidence) and more workforce development and nonprofit infrastructure (which have almost none). The undisclosed third isn’t dropped: her essays give each year’s total, so the residual is a known dollar amount, spread over that year’s undisclosed gifts in proportion to the recipient’s pre-gift IRS 990 revenue raised to an elasticity fit on the disclosed pairs, with the fuzzy name-to-EIN matches audited by a third model, a small one, against the live API. That fit is a finding in its own right: across 1,313 disclosed gift–revenue pairs, gift size scales with organization revenue to the power 0.41 — a 10× bigger organization gets about 2.5× more money. Her giving is far flatter across organization size than proportional. The imputed third moves each cause share by at most ~1.5 points — the disclosed two-thirds was representative.
The largest correction came from a reader. The model originally priced every health dollar at US anchors, so her gifts to organizations delivering abroad — Malaria Consortium, GiveDirectly’s global program, Living Goods, Muso, Amref, Partners In Health, Evidence Action — were understated by orders of magnitude: bed nets at Medicaid rates. Health dollars now split by each organization’s reported service locations, with the non-US share (~5% of her giving) priced at global-health anchors. That one fix tripled the skeptical median, from ~70,000 to ~205,000 QALYs, and it means most of the model’s measured health impact comes from the small slice of her portfolio that reaches low-income countries.
None of the model code was hand-written; the whole thing was natural-language prompting. For transparency, here is every prompt I typed, verbatim — typos and all.
Appendix: the prompts
To Claude Code:
- estimate the qaly impact of mckenzie scott’s lifetime donations
- do better than judgment calls. make an actual quant analysis givewell-cea style. make a repo for it if thats useful
- no just qalys for now. and considfer evidence quality especially causal identification credibility
- /cycle
- shall we make it an interactive and put it on maxghenis.com (using all the design tokens)? like a real py package with ci, nextjs/tailwind etc
- inline link any falsifiable claims ALWAYS ALWAYS REMEMBER THIS
- whats the global frontier
- is it a falsifiable claim
- fix
- codex made some changes wdyt
- give me a prompt for it to fix. but i think there was a misunderstanding i didnt ask for a qaly/daly change, could we centralize around one? which?
- if you were starting this project from scratch howd you do it
- yes
- do a full review of this, both you and with a sol subagent
- yep go - and dont have anyu allegiance to existing code, feel free to rebuild any and all things froms cratch
- do it all
- make sure the prose isnt bogged down by the history - like it seems like leading with the inflation adjustment in the tool is just based on it having been a bug we just fixed. users should see the tool first thing when they get to the page
- can we give the blog post like a button at the top to use the tool, like we do for rambar etc
- whats the delta against givewell? noting scaling limitations etc
- sure yeah does it belong in the blog or the tool? like you could imagine a bigger version of the tool that also combines it with givewells for a general qaly estimator for every intervention and portfolio but not now
- Vs. global frontier / 1,212× / more health per marginal $ — this makes it sounds like scott’s is 1212x more effective
- maybe we should drop the card and just discuss it in the written stuff…
- then could you just make the 90% interval below in small text instead of a separate card, also add to the $/qaly
- i dont get these two - whats the 2.1x wrt? whats 64.2b?
- scott doesnt publish any dollars by cause? i thought she at least published her list of orgs, like are we basing this on any real data?
- undisclosed ones can we do some research on, if need be we could scale by total revenue in the relevant year from 990s
- what model are we using for this
- i dont think we need fable for this fan out do we? could probably do like 5.6 terra or something
- yeah terra is the small codex tier, use it for the audit
To Codex:
- review the math/assumptions in https://maxghenis.com/mackenzie-scott-qaly (its a local repo)
- would py wasm be more parsimonious and dry
- fix it all
- deployed?
- yes do
The model, tests, and sources are on GitHub.